DBのschema情報をAI agentで参照できるようにする
背景
Claude CodeなどのAI agentでSQLを書かせたい時、スキーマ情報を提供することで精度を大幅に向上させることができます。
migrationファイルによる管理はしていますが、履歴情報なので現在のスキーマ情報を把握するためには全てのファイルを考慮する必要が出てきてしまいます。
そこで、最新のスキーマ情報を取得して参照できるような仕組みを構築しました。
色々な方法が考えられると思いますが、今回は最新情報を引っ張ってきてGit管理する仕組みにしています。
今回対象としたのはMySQLとSnowflakeの2つです。
実装内容
現プロダクトではschemas配下にschemas/mysqlとschemas/snowflakeというディレクトリを作成していて、ここでgolang-migrationで使用するmigrationファイルを管理しています。
各schemaファイルはこの配下に配置することにしました。
MySQLのスキーマ情報の自動出力
以下のコマンドを使用してMySQLの現在のスキーマを取得するようにしています。
mysqldump -h 127.0.0.1 -P 3306 -u docker -pdocker {{.DATABASE_NAME}} --no-data --no-tablespaces > schemas/mysql/schema.sql接続先はlocalのDBコンテナにしています。
コマンドを実行する際にlocalのDBコンテナのmigration情報が最新じゃない場合は最新のschemaにはならないですが、用途を考えても大きな問題にはならないと思うので手軽さ重視で一旦これで良しとしています。
実際にはTaskfile.ymlに以下のように登録してタスクとして利用できるようにしました。
mysql-schema:
desc: 現在のDBスキーマ状態をファイルに反映させる。3306ポートのDBコンテナが起動している必要がある
cmds:
- mysqldump -h 127.0.0.1 -P 3306 -u docker -pdocker {{.DATABASE_NAME}} --no-data --no-tablespaces > schemas/mysql/schema.sqlSnowflakeのスキーマ情報の自動出力
snowflakeの方はmysqldumpのような便利なコマンドが見当たらなかったので、スクリプトを作成してそれを実行する方針としました。
全てのテーブル定義を1つのファイルに出力するとファイルサイズが大きくなってしまうので、今回はschemaごとにファイルを分ける方針としました。
schemaが増えたりした場合は追加作業が必要になりますが、頻度や用途を考えると特に問題にならないと判断しています。
#!/bin/bash
get_private_key() {
echo $(aws ssm get-parameter \
--name /path/to/private-key \
--query 'Parameter.Value' \
--with-decrypt | tr -d '"')
}
declare -a DB_SCHEMA_COMBINATIONS=(
"DATABASE_1:SCHEMA_1:schemas/snowflake/DATABASE_1/SCHEMA_1"
"DATABASE_1:SCHEMA_2:schemas/snowflake/DATABASE_1/SCHEMA_2"
"DATABASE_2:SCHEMA_3:schemas/snowflake/DATABASE_2/SCHEMA_3"
"DATABASE_2:SCHEMA_4:schemas/snowflake/DATABASE_2/SCHEMA_4"
)
for combo in "${DB_SCHEMA_COMBINATIONS[@]}"; do
IFS=':' read -r database schema output_dir <<< "$combo"
output_file="$output_dir/schema.sql"
SNOWFLAKE_ACCOUNT="ACCOUNT_ID" \
SNOWFLAKE_USER="USER_NAME" \
SNOWFLAKE_DATABASE="$database" \
SNOWFLAKE_SCHEMA="$schema" \
SNOWFLAKE_PRIVATE_KEY="$(get_private_key)" \
ROLE="ROLE_NAME" \
WAREHOUSE="WAREHOUSE_NAME" \
go run ./scripts/go/update_snowflake_schema "$output_file"
done実際にはgosnowflakeを使用してsnowflakeから情報を取得するので、以下のgoのscriptを呼び出しています。
必要な部分だけ抜粋しています。
func writeFile(file io.ReadWriter, config *gosnowflake.Config, db *sql.DB) error {
fmt.Printf("processing schema... %s.%s\n", config.Database, config.Schema)
fmt.Fprintf(file, "-- Schema information for %s.%s\n", config.Database, config.Schema)
fmt.Fprintf(file, "-- Generated from: %s\n", "./scripts/go/update_snowflake_schema/main.go")
fmt.Fprintf(file, "\n")
fmt.Fprintf(file, "-- ===================================\n")
fmt.Fprintf(file, "-- TABLE LIST\n")
fmt.Fprintf(file, "-- ===================================\n")
fmt.Fprintf(file, "\n")
// 各databseの`INFORMATION_SCHEMA.TABLES`から`TABLE_SCHEMA`を指定して全てのtablesを取得
tables, err := getTables(db, config.Database, config.Schema)
if err != nil {
return fmt.Errorf("failed to get tables: %w", err)
}
for _, table := range tables {
comment := ""
if table.Comment.Valid {
comment = fmt.Sprintf(" -- %s", table.Comment.String)
}
fmt.Fprintf(file, "-- %s (%s)%s\n", table.TableName, table.TableType, comment)
}
fmt.Fprintf(file, "\n")
fmt.Fprintf(file, "-- ===================================\n")
fmt.Fprintf(file, "-- DDL STATEMENTS\n")
fmt.Fprintf(file, "-- ===================================\n")
fmt.Fprintf(file, "\n")
for _, table := range tables {
if table.TableName == "schema_migrations" {
continue
}
// `GET_DDL`を使用して各tableのDDLを取得
ddl, err := getDDL(db, "TABLE", fmt.Sprintf("%s.%s.%s", config.Database, config.Schema, table.TableName))
if err != nil {
logger.Log.Warnf("Failed to get DDL for table %s, trying to construct from column info: %v", table.TableName, err)
continue
}
fmt.Fprintf(file, "-- Table: %s\n", table.TableName)
fmt.Fprintf(file, "%s\n\n", ddl)
}
return nil
}やっていることは単純で、dababase, schemaごとに全tableを取得し、それをループで回しながらsnowflakeのGET_DDLの結果をファイルに吐き出しています。
CLAUDE.mdでの参照設定
ここまででMySQLとSnowflakeのschemaファイルの生成ができるようになったので、あとはこれをClaude Codeで正しく参照できるようにします。
CLAUDE.mdに以下のようにpathを記載しました。
## Schema
### MySQL
- **Schema File**: `schemas/mysql/schema.sql` - Current database schema for SQL development
### Snowflake
Snowflake schemas are organized by database and schema for analytics and data warehouse operations:
#### Database1
- **DATABASE_1**: `schemas/snowflake/DATABASE_1/SCHEMA_1/schema.sql` - SCHEMA_1 data
- **DATABASE_1**: `schemas/snowflake/DATABASE_1/SCHEMA_2/schema.sql` - SCHEMA_2 data
#### Database2
- **DATABASE_2**: `schemas/snowflake/DATABASE_2/SCHEMA_3/schema.sql` - SCHEMA_3 data
- **DATABASE_2**: `schemas/snowflake/DATABASE_2/SCHEMA_4/schema.sql` - SCHEMA_4 data sharing schema
...動作確認
claude codeで何のコンテキストも与えずにラフに特定のschemaのテーブル一覧を出力させたら正しく出力してくれました。
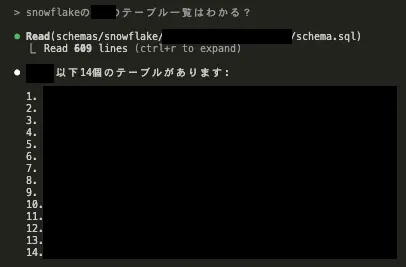
特定のテーブルのカラム情報についても正しく出力してくれてます。
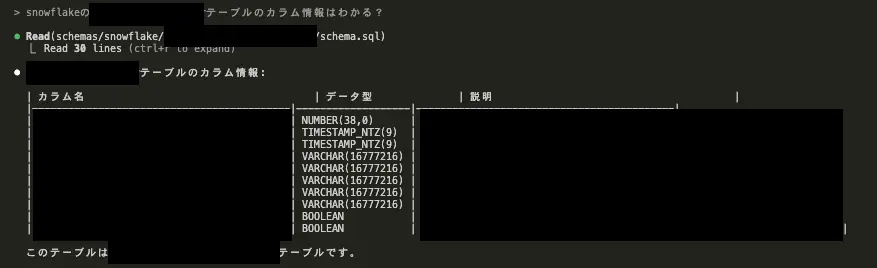
これであればSQLを書く際にもうまく参照してくれるのではと期待してます。
運用方針
今回は手動でコマンドを実行して最新情報をファイルで取得し、それをGit管理して都度更新する方針としました。
CIなどで情報が最新かチェックすることも可能ですが、頻度やユースケースを考慮して、必要になったら手動で最新にアップデートする運用で十分と判断しました。
まとめ
MySQL、Snowflakeのスキーマ情報を半自動的に取得できるようにしたことで、AI agentが参照できる土台を構築しました。
スキーマ情報をラフに自然言語で聞くこともできますし、SQLを生成してもらう時も精度が上がるのではと期待しています。
最近はAI agentが力を最大限に発揮できるようにするための仕組みづくりという、ルンバブルな環境を整えることに注力してます。
